This article describes exploiting a per-rank binding when using a "rankfile" with OpenMPI jobs and hybrid jobs using OpenMP in Univa Grid Engine 8.1
That compute jobs can improve performance when operating scheduling for the job is turned off and the processes are bound to a fixed set of processors is not new. In Sun Grid Engine 6.2u5 we therefore built-in a core binding feature, which allows to pin jobs to specific processors. This feature evolved over time and is since UGE 8.1 a part of the Grid Engine scheduler component itself.
Levels of CPU Affinity
When compute jobs are bound to processors the complete UGE job is bound per default to the selected set of CPU cores. Hence when you have a four way parallel job with four threads and they are bound to four CPU cores by Grid Engine, the threads itself can still change the cores within the subset of cores selected. What you basically have at this stage is a course grained per job binding. The following picture illustrates this situation: On a two socket execution host the job is bound to the first core on the first socket as well as to the first core on the second socket. When the application has two processes both are allowed to run on both cores. Hence the processes can change the sockets. In this example the job submission was done by using the „-binding striding:2:4“ qsub option (i.e. on each host the job is running it is bound on two cores with a distance of four).
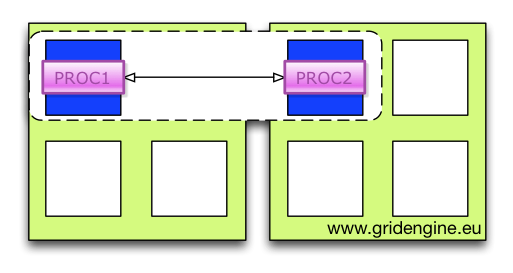
The next level of binding is a per process binding. Since Grid Engine knows nothing about the job (how many processes or threads are created finally) during submission and scheduling time, this binding is usually done by a parallel run-time system, like OpenMPI.
So how can OpenMPI interact with Grid Engine? In Univa Grid Engine 8.1 the scheduler knows everything about the host topologies and the CPU cores which are used by other jobs hence UGE does a good job in pre-selecting the cores for a per job, depending on other jobs running in the system, without doing the actual binding itself. This can be done by using the "-binding pe" qsub submission parameter. The selected cores are then made available in the "pe_hostfile" as well as in teh SGE_BINDING environment variable. The provided information can be exploited by the run-time system of the job. OpenMPI supports this by a so called „rankfile“ which can be passed to the mpirun command. It contains a mapping of a single MPI rank to a specific core on a specific socket. Univa Grid Engine can generate such a rankfile by adding a conversion script to the parallel environment.
An example template with a pre-configured conversion script is part of the Univa Grid Engine 8.1 distribution. The template as well a the shell script and a README can be found in the $SGE_ROOT/mpi/openmpi_rankfile directory. All what you have todo is adding the template into Grid Engine and adding the newly generated openmpi_rankfile parallel environment to your queue configuration.
> qconf -Ap $SGE_ROOT/mpi/openmpi_rankfile/openmpi_rankfile.template
> qconf -mq all.q <-- adding the PE in the queue configuration
If you want to adapt your parallel environment yourself, all what you have to do is to add the path to a conversion script, which parses the pe_hostfile for the selected cores (fourth column in format <socket>,<core>:...) and does a mapping between cores and ranks. Then the rankfile must be written into $TMPDIR/pe_rankfile.
In order to pass the generated information to OpenMPI, mpirun must contain the option „--rankfile $TMPDIR/pe_rankfile“. In order to submit the parallel program you have to call
> qsub -pe openmpi_rankfile 4 -binding pe striding:2:4 -l m_topology=“SCCCCSCCCC*“ yourmpiscript.sh
This selects two socket four core machines for the job (m_topology) and requests two cores on each machine (with a step-size of four) for binding (striding:2:4), and four slots in total. Hence the job will run on two machines since the allocation rule of the parallel environment is two (i.e. two slots on each host).
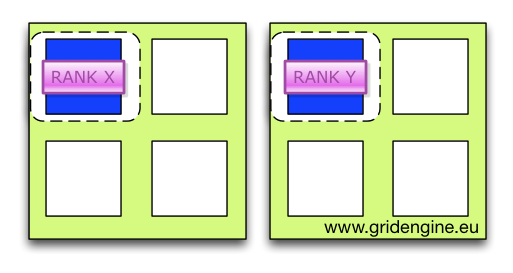
Since two slots for a machine are chosen as well as two cores the conversion script assigns each rank a different core. Now each rank will be bound to a different core. This can be tested with the taskset -pc <pid> command. It shows for the process given by <pid> the core affinity mask.
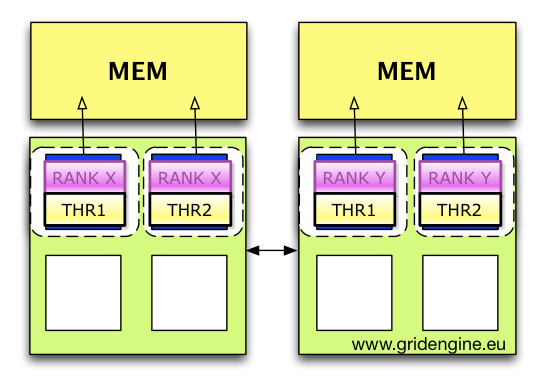
But this is not the end of the story. Each MPI rank could contain parallel code like OpenMP statements itself and therefore it is needed that one rank needs two have more cores like shown in the next illustration.
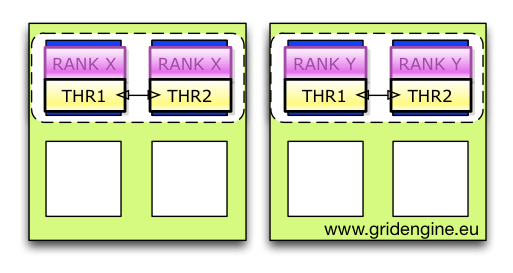
Here each rank got two cores from the rankfile (for this situation the program/script must be slightly adapted) and two ranks are placed on one machine. Each rank / or process can contain multiple threads and there is a need to bind each of the threads to its own core. After applying the rankfile binding now the more fine grained per thread binding must be performed (based on UGE selected cores).
In the following example OpenMP is used for thread parallel processing within each rank. The gcc OpenMP implementation is using the GOMP_CPU_AFFINITY environment variable in order to bind threads on cores. The environment variable contains a list of processor IDs which are chosen by the run-time system for thread binding. Fortunately all forms of core binding (pe, env, set) provided by Univa Grid Engine 8.1 are setting the SGE_BINDING environment variable which contains a space separated list of the selected logical CPU cores as processor IDs. But when having two ranks per host it contains all cores selected for the host as available for the job. Hence the full list must be converted so that each rank just gets a subset of them. This must be done in the OpenMPI job script (which is called by mpirun) itself since it needs the information about the specific rank number chosen. This information (i.e. the rank number itself) is used to split the processor list into two parts (even rank numbers get the first two cores uneven ones the remaining two cores on a host). The following shell code sets the GOMP_CPU_AFFINITY for each rank.
#!/bin/bash
# set path to openmpi lib
export LD_LIBRARY_PATH=/usr/local/lib
export PATH=$PATH:/usr/local/bin
# expecting 2 ranks per host and 4 cores selected, first one gets first 2 cores
if [ $(expr $OMPI_COMM_WORLD_RANK % 2) = 0 ]; then
export GOMP_CPU_AFFINITY=`echo $SGE_BINDING | tr " " "\n" | head -n 2 | tr "\n" " "`
echo "Rank $OMPI_COMM_WORLD_RANK got cores $GOMP_CPU_AFFINITY"
else
export GOMP_CPU_AFFINITY=`echo $SGE_BINDING | tr " " "\n" | tail -n 2 | tr "\n" " "`
echo "Rank $OMPI_COMM_WORLD_RANK got cores $GOMP_CPU_AFFINITY"
fi
# start the OpenMPI programm
/home/daniel/scripts/a.out
This script is started by following job script.
#!/bin/sh
# show hostfile and rankfile for debugging purposes
echo "pe_hostfile"
cat $PE_HOSTFILE
echo "pe_rankfile created by create_rankfile.sh scripts configured in GE parallel environment"
cat $TMPDIR/pe_rankfile
echo "SGE_BINDING is $SGE_BINDING"
mpirun --rankfile $TMPDIR/pe_rankfile /home/daniel/scripts/openmpi_hybrid.sh
Finally the binding looks like in the next picture.
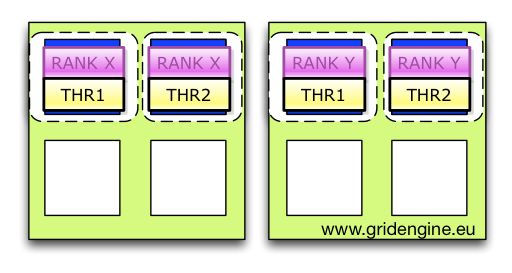
If you have one rank per host but multiple OpenMP threads per rank it is much easier. The only thing you have to do is to set OpenMP environment variable to the adapted content of the SGE_BINDING variable in the mpirun script.
export GOMP_CPU_AFFINITY=`echo $SGE_BINDING`
echo "GOMP_CPU_AFFINITY is set to $GOMP_CPU_AFFINITY"
In order to squeeze out some additional percentages of performance a job can be forced to take only directly connected memory (and not going over the quick-path interconnect through other sockets to memory with a higher latency). This is done by adding the new "-mbind cores:strict" parameter in Univa Grid Engine 8.1 during job submission.
UPDATE: 09/05/2012
While playing with a new "toy" ;-) I figured out that the GOMP_THREAD_AFFINITY settings above does not work correctly on all system types. GOMP_THREAD_AFFINITY accepts CPU ids while SGE_BINDING reports logical core numbers. This must be taken into account when having a Intel box with hyper-threading activated. Hence the SGE_BINDING core number must be first converted into the OS CPU number. This can be done by the Grid Engine "$SGE_ROOT/utilbin/lx-amd64/loadcheck -cb" command. It puts out all conversion needed. Since it takes a short moment to run the mapping can be also stored in the filesystem.
Here is the output for a hyper-threading box. As you can see logical core 0 must be mapped to CPU id 0 and 16.
...
Internal processor ids for core 0: 0 16
Internal processor ids for core 1: 1 17
Internal processor ids for core 2: 2 18
Internal processor ids for core 3: 3 19
Internal processor ids for core 4: 4 20
Internal processor ids for core 5: 5 21
Internal processor ids for core 6: 6 22
Internal processor ids for core 7: 7 23
Internal processor ids for core 8: 8 24
Internal processor ids for core 9: 9 25
Internal processor ids for core 10: 10 26
Internal processor ids for core 11: 11 27
Internal processor ids for core 12: 12 28
Internal processor ids for core 13: 13 29
Internal processor ids for core 14: 14 30
Internal processor ids for core 15: 15 31
...
NUMA topology : [SCTTCTTCTTCTTCTTCTTCTTCTT][SCTTCTTCTTCTTCTTCTTCTTCTT]
NUMA node of core 0 on socket 0 : 0
NUMA node of core 1 on socket 0 : 0
NUMA node of core 2 on socket 0 : 0
NUMA node of core 3 on socket 0 : 0
NUMA node of core 4 on socket 0 : 0
NUMA node of core 5 on socket 0 : 0
NUMA node of core 6 on socket 0 : 0
NUMA node of core 7 on socket 0 : 0
NUMA node of core 0 on socket 1 : 1
NUMA node of core 1 on socket 1 : 1
NUMA node of core 2 on socket 1 : 1
NUMA node of core 3 on socket 1 : 1
NUMA node of core 4 on socket 1 : 1
NUMA node of core 5 on socket 1 : 1
NUMA node of core 6 on socket 1 : 1
NUMA node of core 7 on socket 1 : 1
Update:
If you have Intel developer tools installed, you can also use the Intel "cpuinfo" tool for getting the OS internal processor ID out of the "logical core" id. "cpuinfo -d" does a node decomposition and shows packge id (socket number), cored ids (the logical ones) and processors (as pairs when hyperthreaded). But you still need to multiply the package ID with the core ID in order to get the "absolut logical core ID" and then have a look at the right processor pair entry.